")









联系我们:186 6505 3298




Optistruct软件算法有哪些?
模态快速算法
在5.2节中已经介绍了特征值算法,包括anczos特征值算法和AMSES 模态求解加速算法Lanczos 求解器的精度非常高,对于中等规模的模型计算效率也比较高,因此在20世纪90年代以后成为标准的模态求解器之一。然而随着车身NVH分析需求的增加以及车身网格数量的增加,人们发现 Lanczos 对于存在内声场的声固耦合分析效率较低,对于整车NTF等分析效率很低。21世纪初开始,多层子结构特征值算法(Multi-level Sub-structuring Eigensolver Solution)成为模态求解的主流算法,特别是对于大型模型和声固耦合分析,多层子结构特征值算法体现出很大的求解效率优势。
Optistruct AMSES是自动多层子结构特征值求解器的简称。相比Lanczos算法,AMSES 在需要计算大量模态或者处理大规模自由度模型时计算效率更高,而且可确保得到与Lanczos 算法近乎一致的结果。AMSES的加速效果与待求解的特征向量自由度有关,在仅需要得到部分自由度响应的计算中(如大部分NVH应用),加速效率将得到极大的提高,部分情况下可达到Lanczos方法的10~100倍。
并行算法
Altair OptiStruct高性能计算包含以下几种并行架构和算法。
l SMP:Shared Memory Parallelization,共享内存并行。
l DMP:Distributed Memory Parallelization,分布式内存并行。
l GPU:采用图形处理器执行并行计算。
l Hybrid:以上方式的混合并行模式,分为SMP+DMP和SMP+GPU。除了分析计算任务的并行之外,OptiStruct针对多模型优化(MMO)和失效安全拓扑优化(FS0)这两种优化类型还推出了相应的特殊并行算法,关于优化的并行计算可参阅《OptiStruct及HyperStudy 优化与工程应用》,这里不再赘述。
1.SMP
SMP指的是在单一计算节点上使用共享内存进行多线程并行计算,在0存储上具有单一的内存地址空间,在计算上通过多核并行方式进行,如图26-4所示。通常在仅有一个计算节点的情况下使用该方式。0iStructSMP支持所有的仿真分析及优化类型。
使用SMP时,需要添加参数-nt(或-nepu/-nt-hread),相应任务提交命令如下。
1)在 Windows 系统中使用命令:
ALTAIR_HOME/hwsolvers/scripts/Optistruct, bat
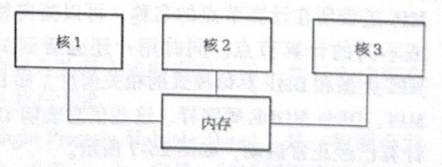
图26-4 SMP架构
file. fem -nt 4
2)在Linux系统中使用命令:
$ ALTAIR HOME/scripts/optistruct file. fem -nt 4
3)使用 HyperWVorks Solver Run Manager 对话框,在Optistruct文本框中填写-nt 参数,如图26-S所示。
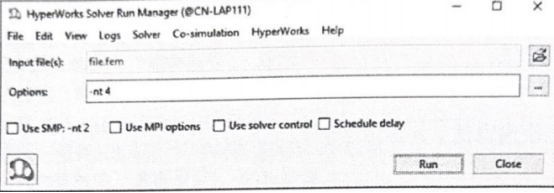
图26-5在HyperWorks Solver Run Manager 对话框中提交Optistruct SMP 计算
OptiStruct 在4~32 核之间的 SMP计算能获得较高的加速比,多于32 核的SMP 计算可以看到加速效果,但加速比有所下降。
2. DMP
DMP指的是在一个或多个计算节点上运行若干个基于MPI的OptiStruct进程(简称MPI进程)。如图26-6所示,每个MPI进程都有各自的内存空间并通过 MPI进行通信。高效的DMP计算要求每个MPI进程都必须具备充足的内存空间来执行计算任务,同时还需具备稳定高效的通信方式。OptiStructDMP 支持静力学、屈曲分析、优化、疲劳和非线性分析等大多数工况。使用 DMP时,只需要添加-np参数,相应任务提交命令如下。1)在Windows系统中使用命令:
$ ALTAIR HOME/hwsolvers/scripts/OptiStruct. bat file. fem -np 4
2)在 Linux 系统中使用命令:
$ ALTAIR HOME/scripts/Optistruct file. fem -np 43)使用 HyperWorks Solver Run Manager对话框,在Options中填写-np 参数。需要注意的是,由于是分布式内存,每个MPI都会有一个独立的内存空间,作业整体的内存空当间是所有 MP所占内存空间的总和,因此有效的MPI并行计算必须以足够的内存空间为前提。
物理内存较少时,推荐采用 SMP 计算方式。使用-np参数提交计算时,Optistruct默认使用Intel MPI。如果需要自定义 MPI类型,可以添加参数-mpi。其中,-mpii表示 Inte! MP,-mpi ms 表示 MS-MPI,-mpi pl 表示 IBM/HP MPl,-mpi pl8表示 yer8 及更新的 IBM-MPI。
计算任务启动后,可以在相应的.ou文件中看到各MP进程的分配情况。其中HOSTNAME为MPI进程所在计算节点的名称,可以指向相同或不同的计算节点。同时用户还会看到关于MPI类型和 DMP具体模式的相关信息,如IntelMPI、DDMMODE等字样。这些信息表明DMP计算已经正常启动,如图26-7所示。
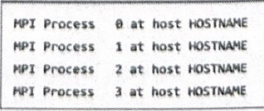
图26-7 DMP计算的MPI进程
使用-np参数提交计算时,Optistruct默认同时启用域分解方法参数-ddm,即 DMP计算默认采用DDM(Domain Decomposition Method)方式。DDM 是基于 MPI的并行算法,支持广泛的分析和优化类型。DDM计算中,MPI有两个层次的数据交换。
l Level1:域分解第一层级,基于任务、载荷或工况的分解。
l Level 2:域分解第二层级、基于几何的分解,更确切地说,是基于自由度的分解,如图 26-8所示。
通常情况下,用户指定-np的值之后Optistruct会根据模型和工况等信息自动进行Level1和Level2的划分,不需要用户来干预。Optistruct也引人了MPI分组的参数DDMN-GRPS,用户可以使用PARAM、DDMNGRPS来控制 DDM 运行的层级。当设置DDMNGRPS为MIN 时,将完全采用Level2方式运行;当设置DDMNGRPS为MAX时,将优先采用Level1方式运行;也可以设定一个数值来自定义Level1的分组数目。默认情况下,DDMNGRPS 参数的值为AUTO,即由OptiStruct根据模型信息来自动分组。
MPI进程通过必要的通信保证了计算结果的准确性,不管采用何种DDM运行方式,求解完成后都将生成统一的.ou及.h3d等结果文件。对于用户来说,不论是否采用及如何使用DDM,都将得到相同的结果。
3.GPU
当一台计算节点上具有适用于高性能计算的GPU时,强大的GPU计算能力将有助于大规模稀疏矩阵的求解,如图26-9所示。OptiStruct支持使用GPU进行并行计算,可以采用1个或同时采用多个 GPU 进行计算以提高计算性能。
OptiStruct GPU 支持线性静力学分析及对应的优化分析,支持采用AMSES或 Lanczos算法的模态及屈曲分析。GPU在求解大模型的万阶以上的模态数量时可以获得较高的加速比。在以体单元为主的模型的静力学分析中,也能获得一定的加速比。
使用 GPU方式时,只需要添加-gpu及-ngpu参数即可。
1) 在Windows系统中使用命令:S ALTAIR HOME/hwsolvers/scripts/Optistruct, bat file, fem -gpu -ngpu 2
2) 在 Linux系统中使用命令:
$ ALTAIR HOME/scripts/Optistruct file, fem -gpu -ngpu 2
3)使用 HyperWorks Solver Run Manager 对话框,在 Options 中填写-gpu、-ngpu 参数。其中,-gpu 参数是必需的,-ngpu为可选参数,对于多GPU的计算节点,可以指定参与计算的GPU 个数。示例命令中的参数表示同时调用了两个 GPU执行计算,而每个 GPU 中通常包含上千个计算单元。目前,0pliSuruc 支持的用于高性能计算的GPU包括基于Kepler、Maxwell、Pascal、Volta架构的 Tesla 及 Quadro 系列显卡。
4. Hybrid
在实际工程应用中,综合使用SMP、DMP和GPU的混合并行方式能实现比单一并行方式更高的加速比。下面介绍Optistruct最常用的 SMP+DMP 混合并行方式。SMP+DMP 混合并行在Optistruct中称为 SPMD(Single Program Multiple Data),是一种混合共享/分布式内存并行(Hybrid Shared/Dislributed Memory Parallelizalion)。它是一种适用面广且高效的。
5)可以通过.out文件查看自动评估的内存需求情况。这些信息在任何一次计算的.out文件中都可以看到。图 26-10所示为一段典型的自动评估计算所需资源的结果,可以看到,Optistruct对于提交的模型自动评估之后认为in-core 模式需要11827MB 内存。

图26-10检查out 文件:计算资源需求
使用 in-core 模式进行高性能计算可以全力发挥CPU的计算性能,同时也需要充足的内存。倘若内存不足以支撑 in-core 模式计算,则需要采用 out-core 或 min-core 模式。在.out 文件的开头,会提供当前计算节点的可用内存及SWAP资源情况。用户应当依据硬件资源情况选择合适的内存和运行设置。如图26-11所示,.out 文件显示当前系统可用RAM为11912MB,SWAP为28269MB。将其与图26-10 进行对比,可知此时RAM 满足in-core 模式的内存需求,可以使用-core in 参数进行计算。

图26-11检查.out文件:计算节点的当前资源
in-core 模式所需的内存可以通过 check run来查询,在正式计算时也会在.ou 文件中显示。模型本身规模、算法等都会影响计算内存需求,因此建议在正式计算前添加-check的运行选项,执行一次模型检查,并查看.out 文件。下面分别给出了SMP及DMP并行模式下的模型检查命令采用 SMP 模式提交 check run 的方法如下。
1)在 Windows 系统中使用的命令如下,-n后的数字根据实际情况而定,
$ALTAIR HomE/hwsolvers/scripts/Optistruct, bat file, fem -nt 4 -check
2)在 Linux 系统中使用的命令如下,-nt后的数字根据实际情况而定$ ALTAIR HOME/scripts/Optistruct file, fem -nt 4 -check
check 模式得到的.out 文件包含求解器版本、计算机硬件配置、模型单元与节点信息、以及计算所需的内存与硬盘等信息,并推荐了采用 DMP模式时的-p值,如图 26-10 所示。采用 DMP模式提交 check run 的方法如下。
1)在Windows系统中使用的命令如下,-p/-nt后的数字根据实际情况而定$ ALTAIR HomE/hwsolvers/scripts/optistruct, bat file. fem -np 2 .check2)在 1inux 系统中使用的命令如下,-p/-n后的数字根据实际情况而定
$ ALTAIR HOME/scripts/optistruct file, fem -np 2 .check
check 模式得到的.out 文件包含了当前 MPl中 im-core、out-core 模式下所需的内存,及所有 MP在一台计算机上运行时所需的内存,并推荐了-np值,如图26-12所示。

图26-12 SPMD模式下的.out文件信息
2.内存选项-len
该参数用于定义动态内存扩展上限。
1) -en是 OptiStruct最基础的内存参数。当用户未设置任何内存选项时,OptiStruct自动采用-len选项,其默认值为8000,即8GB。
2) -len与-core 同时使用时,-core 具有更高的优先级,-len 将不发挥作用。
3) 仅设置了-len,而没有设置-core 时,若in-core 模式所需内存小于-len 的值,将采用in-core模式执行,否则将采用 out-core 或 min-core 模式执行。
4)一般情况下,推荐用户直接优先设置-corein选项。对于大中型的模型,不推荐使用-en 选项,也不推荐不设置任何内存选项。
3. 内存选项-minlen该选项定义动态内存分配的最小值,单位是MB。默认情况下-minlen取值为10%的-len 值。
1)-minen 可以用于预分配一定数量的内存,避免动态内存扩展导致的计算效率降低或其他应用程序抢占资源的问题。
2)可与-core in并存。
3)OptiStruct在某些特定情况下(如在进行NVH的节点贡献量计算时),自动内存估算存在比实际需求少的现象,有时候会导致计算失败而报错退出。这时候的解决办法就是设置-minle”,预分配一定数量的内存。比如对于常见的整车NVH节点贡献量计算,可以设置-minlen100000,即预分配100GB内存。当用户遇到-corein内存出错而又无法确切获知计算所需的内存数时,可以将-in-len 的值设置为物理内存的90%~95%,只留少量内存供系统正常运行即可。
4)该参数的另一个优势是设置灵活。常规的内存选项通过命令行参数的形式来实现,这对于某些应用场景会非常不方便。比如用户通过企业统一作业调度系统(如PBSPRO)进行作业提交时,如果作业调度系统在提交页面没有集成内存参数,使用者就没有办法进行内存设置。这时必须寻求HPC管理员的帮助,才能在后台通过命令行提交作业,或者必须寻求作业调度系统集成商的帮助。-minlen的好处是该参数既可以通过命令行参数使用,也可以通过SYSSETTING(MINLEN=#)卡片在.fem模型文件中直接指定,这对用户调试计算作业是非常方便的
4. 内存选项-fixlen用户使用该选项可取消动态内存分配,由用户直接设定内存数量,单位是MB。
1)以-6xlen 参数提交求解时,采用的是静态内存设置方式,此时整个求解过程仅进行一次内存预分配,不进行动态扩展,
2)求解器算法将依据固定内存来尽可能选择最快的运行模式
3)若固定分配的内存不足以支撑算法运行,0iStruct将报错退出。
4)使用-fixlen时,不再需要设置-core in、-len 和-minlen。
5)该参数使用不当会造成内存浪费或者软件报错退出,因此推荐仅当物理内存足够时作为用户调试作业使用。
以上4种最常见的内存选项中,-en和-ixlen主要作为0iSumuct的内存默认选项和计算作业调试使用。对于大多数的中大型模型,推荐仅使用-core in内存选项。-minlen选项是物理内存足够而-core in 却报告内存不足时才使用的。
本篇内容取自HyperWorks进阶教程系列的《OptiStruct结构分析与工程应用》,版权归原作者所有,如有侵犯您的权益,请及时联系我们,我们将立即删除。








