")









联系我们:186 6505 3298




OptiStruct什么是HPC 最佳实践?
内存/存储相关选项汇总见表26-1,更详细的说明可进一步查看帮助文档。
表 26-1 内存/存储相关选项
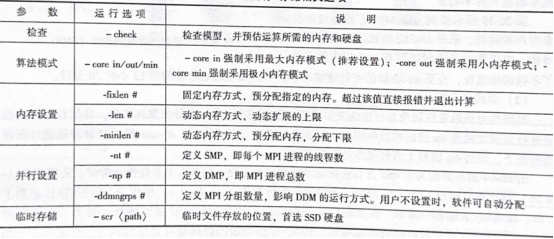
其中,内存设置参数指定的数值为每个MPI进程的内存设置。内存数值#的单位为MB。对于大多数的大中型工程实际问题,为了获得较高的求解效率,应遵循以下原则。
1) 选择合适的硬件。OptiStruct需要高主频CPU 和高读写磁盘,磁盘容量不低于1TB,避免使用远程网络磁盘。
2) 在模态求解及基于模态的其他分析中,优先使用AMSES 模态算法。
3) 在NVH的 ODS(Operating Deformed Shape)计算中,除了采用AMSES 算法外,还推荐使用PARAM,ODS,YES参数。
4) 不管是模态、动力学响应、非线性分析还是优化,优先使用-core in内存选项。
5) 并行计算的算法设置应以优先满足in-core 模式的内存需求为前提。内存不足时,应减小np值,或采用 SMP 模式。
6)并行计算时,SMP模式通常总是有加速效果的,OptiStruct在4~32 核之间进行 SMP 计算时、加速效果会比较明显。常规的NVH计算一般采用8核或16核的SMP计算。
Opismet 并行计算中经常遇到的大型计算有 NVH 分析、非线性分析、多工况线性静力学分析针对这些场景,推荐设置如下。
(1)NVH 分析
NVH 分析主要包括模态分析和模态频响分析,以及基于模态频响分析的各种贡献量分析。这些分析类型的推荐设置如下。
1)采用 AMSES 模态分析方法,即EIGRA 卡片。
2)在.fem文件中设置PARAM,ODS,YES参数。
3)采用SMP模式:-nt8或者-nt16,整车模型较大时可采用-nt 32
4)选用-core in 模式。
当进行节点贡献量分析(PFGRID卡片)时,OptiStruct需要远比其他NVH分析更大的内存量并且此种工况下OptiStruct较难准确评估所需的内存,因此对于节点贡献量分析,建议除了以上设置外、在.fem文件中设置-minlen。
对于常见的整车节点贡献量计算,该选项的一般推荐值为100000,即100GB,用户可根据物理内存和模型大小适当调整。大量的NVH分析实践表明,有效的加速比主要来源于AM-SES模态算法和SMP,DMP通常对VH计算效率的提升并不明显。
图 26-13 所示算例为含 3450万自由度的整车含声腔模型,采用 AMSES 方法进行模态频响分析。可以看到采用SMP时在-nt8以内都获得了不错的加速比,直至-nt 32依然有加速效果,其中,-nt1的运算时间为13 小时20 分钟。
(2)非线性分析
非线性分析通常在混合并行中能获得比较好的加速比。从一些计算案例来看,非线性计算的混合并行加速比随着-np值的增加而增加。在满足单进程(每个MPI)in-core 模式计算所需硬件资源的前提下,提高-np值对于求解效率是有好处的。
图 26-14所示算例为含460万自由度的非线性连续工况,包含3个非线性分析步。采用SMP(nt16)的计算时间为1小时47分钟。采用混合并行模式(-np4-n4)使用16 核时加速比达到了1.86。随着-np分组数的增加,甚至在跨节点并行时,计算效率还在持续增长。需要再次指出的是,-np值的增加会导致内存的持续增加,因此-np值增加的前提是有足够的内存,保证每个MPI都能使用 in-core 模式进行计算。

图26-14 非线性静力学加速比(混合并行)
(3)多工况线性静力学分析
在有些线性静力学分析中,一个模型文件可能包含几十种工况。当这些工况的边界条件相同,仅载荷不同时,有限元模型的刚度矩阵在这几十种工况中完全相同,刚度阵只需要一次分解,此时采用 DDM Level2的计算方式最高效,OptiStruct会自动采用Level2并行方式,即使用户指定了Lev-el1并行方式,OptiStruct也会自动切换到Level2,并在.out 文件中给出切换信息。当这些工况的边界条件不同时,有限元模型的刚度矩阵是不同的,这种情况下需要对所有的刚度矩阵逐个进行分解,Level1及Level2并行都可以使用,一般来说level1的加速效果要优于Level 2.
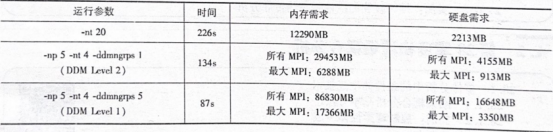
图26-15所示算例为含150万自由度,5种不同边界条件工况的线性静力学分析。采用-nt4的计算时间为254S。可以看到,单纯提高SMP并行核数对于静力学求解效率的提升非常有限,而采用DDM 的方式则有更好的加速效果,且使用Level1的并行效率显著高于Level2。表26-2统计了不同并行方式下的硬件资源需求,可以看出,采用evel1的计算资源需求远大于Level2以及 SMP的硬件需求。

图26-15 多工况静力学加速比(DDMevel1/Level2)
表26-2 OptiStruct分析工况及并行选择
本篇内容取自HyperWorks进阶教程系列的《OptiStruct结构分析与工程应用》,版权归原作者所有,如有侵犯您的权益,请及时联系我们,我们将立即删除。








